Our mapping strategy relies on understanding the processes employed by Facebook to make inferences about their users. One possible way to accomplish that is by having a look at the patents they published.
Finding the data source
There are many institutions and companies that provide access to data regarding patents:
- United States Patents and Trademark Office
- World Intellectual Property Organization
- European Patent Office
- and more.
Google’s database seemed to be the easiest in regards to retrieving data (not only due to the familiar interface, but because the results are structured and it is possible to write the queries in the browser address bar, which makes it quite scrape-friendly – compared to the existing alternatives).

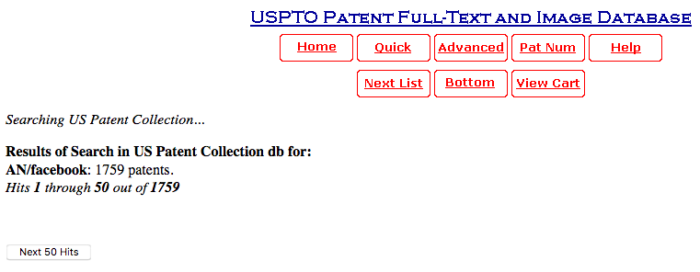
Examining different data sources made clear that the same query can yield different results in each one of the sources. Also, even within one source there is a degree of uncertainty in the results: the csv file provided by Google, for example, did not always contain the same number of patents announced in the results page.
Acknowledging the scale
Depending on the criteria one uses to filter their search, the results can vary from a few dozens to a couple of thousands. One possible search strategy involves searching for terms that reflect the processes we are mapping, like ‘track’, ‘categ’ (from categories, categorization, etc), ‘audience’ and so on.
When speaking of patents published by Facebook, one is speaking of around 5000 entries (and counting). After we selected the patents that contained relevant terms, the results yielded a few hundred patents. But then again, how can one be sure that no important entry is being left out? It could well be possible that there are relevant patents that do not contain any of the terms we searched.
Reading thousands of entries
One possible way to provide an answer to this question would require having an overview of the content of the patents, so that even terms that were not used in the filter would become apparent if they appear frequently enough in the patent description text. It is still not 100% bullet-proof approach, but it offers a wider coverage compared to only using search terms.
The initial idea of a visualization of the relationships between words and patents can be sketched as the graphic below:
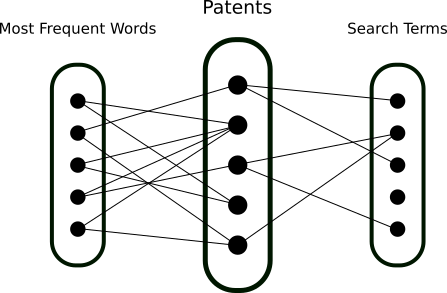
The challenge then becomes accommodating at least 5000 items on a screen, in such a way that it is possible to have an overview and detailed information, at the same time. To start solving this issue, we started sketching a prototype where 3 columns would contain:
- the list of most frequent words
- the list of search terms
- the list of patents
After examining the distribution of patents per year, we saw it could be possible to ‘chop’ the data per year, as the maximum number of patents per year we found so far is around 1000 (way less than 5000!) Below, a demo of the first version of the prototype.

In the second version of the prototype, each patent is not by referencing its id, but as a colored dot (where color indicates, in this example, year of publication). Since the dots occupy less space than the patents ids, it is possible to accommodate much more patents per screen.

As soon as the prototype is a bit closer to what we need, it – or the relevant data report – will be published in this blog.
Understanding the terminology
The terminology surrounding the patents universe is not always self-evident, but nevertheless very relevant for a making good filter. A few examples would be the term priority date and the several ‘kind codes’ (the 2-digit alphanumeric suffix in the patent id, like A1 or B1). The kind code for new, published patents is A1. The other codes refer to specific situations such as a correction of the amendment of documents.
OECD (Organisation for Economic Co-operation and Development) has made available a short and useful glossary of some of these terms.
Related links
Last, but not least, some inspiring links were found along the way:
- lens.org, an open-source initiative aiming to, in the next two years, host “95% of the world’s patent information and link to most of the scholarly literature, creating open public innovation portfolios of individuals and institutions” (source: https://www.lens.org/about/what/, accessed Aug 30, 2017).
- WhoDoTheyServe.com, another open-source initiative that aims to “map the global political, financial and corporate power structure at the highest levels” (source: http://www.whodotheyserve.com/#/about, accessed Aug 30, 2017) .
[…] Lucia and me decided to take a more systematic and scalable approach towards the selection of relevant patents, I performed a manual, preliminary search at Fresh […]
[…] a previous post, we described the initial conditions which gave rise to this approach. Contrary to the single […]