The number of patents in which Facebook is the assignee currently surpasses the 5000. Not all these patents are closely related to our research, certainly – but how to make a good selection amongst such a huge amount of documents? The interface of the service we chose to use made it possible to use filters which certainly help ‘optimize’ the number of results. By using specific search terms, the displayed results are tailored to what one knows to be relevant. But what about the words that one does not know that could also be relevant? How can one have an overview of the existing content while selecting relevant pieces from it? This blog post is a brief overview of how we approached this issue.
Scraping some data
In a previous post, we described the initial conditions which gave rise to this approach. Contrary to the single patent pages, the listing page is not so adequate for scraping. Its content is rendered by javascript and, even though it should be possible to retrieve content using a combination of Python, BeautifulSoup and PhantomJS, a preliminary test did not prove to be successful enough. As a result, we chose to go with the downloadable CSV files that Google makes available at their patents listing page. This solution accommodates our goals and our resources in a well-balanced fashion.
Observations indicate that the maximum number of patents listed by Google in each CSV file revolve around 500. So we divided our search queries into years – and into even smaller periods of time on years where the results would exceed 500 (i.e., from 2014 onwards).
The queries resulted in a series of 26 CSV files (one per year except 2014 onwards, which yielded 4 files per year), each containing basic data about the patents. We then looped through each line of these CSV files and scraped the content of each one of the patents.
Show me the numbers
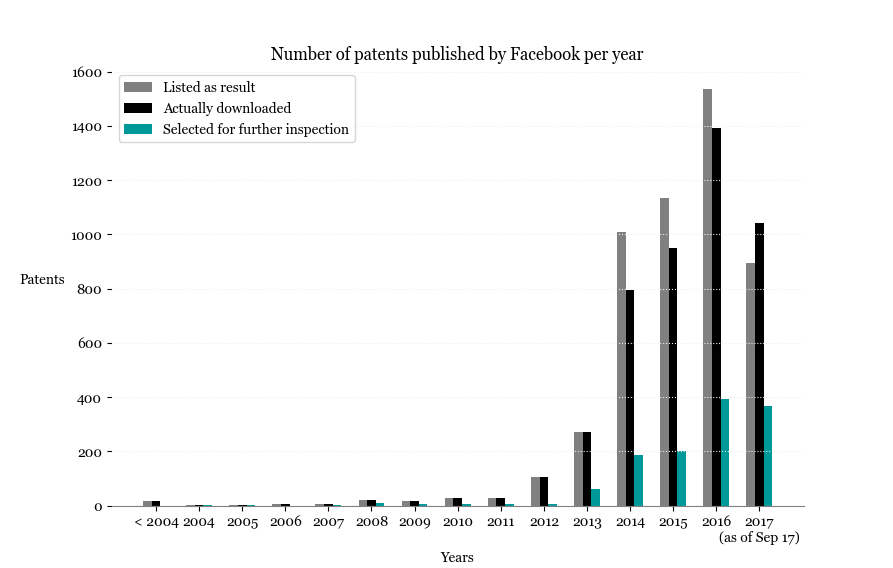
The graph below shows the number of patents published by Facebook per year, according to Google patents (includes older patents that have been originally published by another assignee but later acquired by Facebook):

The different lines represent the results as announced to be in the list versus the actual patents listed in each of the CSV files. While we already knew that Google’s results are not guaranteed to be accurate we believe it is important to have at least an idea of what might be out of our data and on which years these discrepancies seem to be more frequent. (It is nevertheless intriguing that the results are not accurate.)
One important observation (even though somewhat parallel to the main focus of this post) is the obvious increase in the number of patents published after 2011 – 2013 to 2014 and 2015 to 2016 being the intervals where this increase is more evident. It might be worthy to investigate connections between these years and events such as commercial partnerships, amount and origin of investments and changes in Facebook’s terms of service, for example.
Going back to the original intent of the graphic (show the difference between listed results and downloaded content), another observed discrepancy is the one related to the dates used in the query to search for patents. When broken down into years (as in the graph above), the patents listed as result sum up to 5080. However, when searching patents ‘after 01-01-1970 and before 09-18-2017’, the results according to Google amount to ‘around’ 5280 (200 more than the sum of the results displayed when search was broken down into years).
| Query | Listed Patents | Actually Downloaded | Missing | ||
| broken down into years (<2004, 2004, 2005, 2006, etc) |
5080 | – | 4687 | = | 393 |
| encompassing all times (‘after 01-01-1970 and before 09-18-2017’) |
5280 | – | 4687 | = | 593 |
The total missing patents thus, could be between 393 and 593 – roughly between 7 and 11% of the estimated total, which is ‘quite a lot’! In any case, what we wanted to highlight here is that the effort to keep track of data we don’t have is valuable too.
Finally, using data for insights
If you have worked with data before, you know that during the vast majority of time one will be extracting, collecting, munging or processing data and that just a tiny fraction of time is used to actually analyse the data.
A brief recap: our goal was to be able to have a simultaneously broad and detailed overview of the 5000+ patents and relevant words that exist either in the title or in the content: abstract, description, claims. We used words that were pre-selected by us – the search terms – as well as words that belong to the patents content (most frequent words). From there, we should be able to make a(nother) selection of the patents that could potentially be relevant to the research. Our preliminary selection contains 4576 patents (97.63% of the scraped patents).
This overview has been made through a prototype we sketched, which can be broken down into the screenshots below. The 4576 patents are represented by the colored bullets, while the search terms and most frequent words are listed in the corresponding columns.

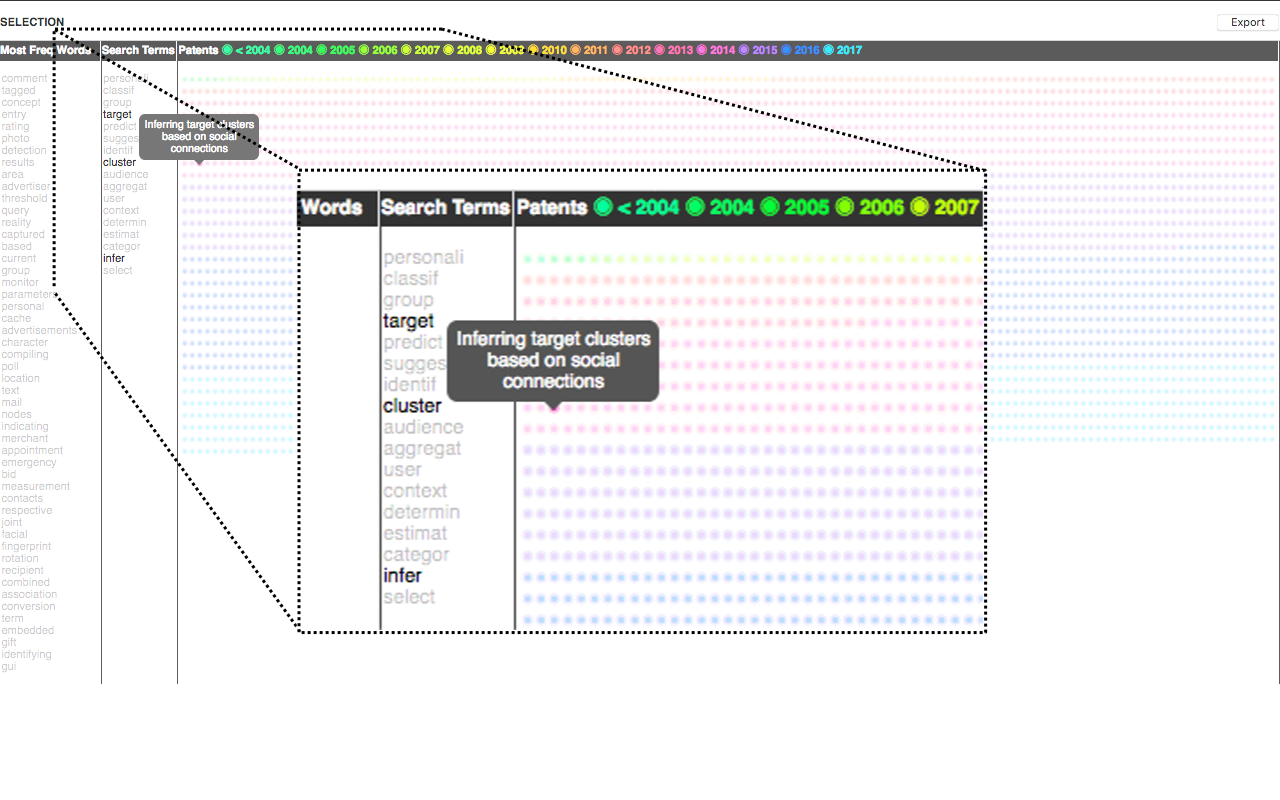


From the 4576 patents, 1242 were actually selected for further inspection, through the prototype. But as explained above, this subset can include patents that are not so relevant to the research but are selected because they contain a word that is relevant in the context of another patent. Here is an updated version of the first graph we showed in this post (broken down as bars, instead of a continuous line):
These 1242 patents were further investigated and flagged as “Must read” or “Maybe”. Patents that do not seem to be relevant to this research were excluded from the selection.
| ‘Must read’ | ‘Maybe’ | ‘Irrelevant’ | Selection via Prototype | |||
| 530 | + | 254 | + | 458 | = | 1242 |
Additional data
This selection generated not only a list of patents that are potentially relevant to our research, but also a list of words that are related to them (17 search terms and 285 most frequent words).
What we described in this post is of course a first step. After reading a considerable number of patents, we should go back to our model and check it, by asking ourselves questions such as:
- Does the model produce good quality results?
- Would there be a more adequate approach (or better parameters) to make this pre-selection?
- How does this selection relate to Google’s ‘similarity’ feature?
[…] going through the process of mining and selecting relevant patents (you can read all about it here), and ending up with 530 “Must Read” patents and 254 “Maybe” patents, I […]