After a brief incursion into LDA, it appeared to me that visualization of topics and of its components played a major role in interpreting the model. In this blog post I will write about my experience with PyLDAvis, a python package (ported from R) that allows an interactive visualization of a topic model.
LDAvis
PyLDAvis is based on LDAvis, a visualization tool made for R by Carson Sievert and Kenny Shirley. They introduce the tool and its elements in this paper and provide a demo in this video. A great amount of information in this blog post is provided by this paper.
In short, the interface provides:
- a left panel that depicts a global view of the model (how prevalent each topic is and how topics relate to each other);
- a right panel containing a bar chart – the bars represent the terms that are most useful in interpreting the topic currently selected (what the meaning of each topic is).
On the left, the topics are plotted as circles, whose centers are defined by the computed distance between topics (projected into 2 dimensions). The prevalence of each topic is indicated by the circle’s area. On the right, two juxtaposed bars showing the topic-specific frequency of each term (in red) and the corpus-wide frequency (in blueish gray). When no topic is selected, the right panel displays the top 30 most salient terms for the dataset.
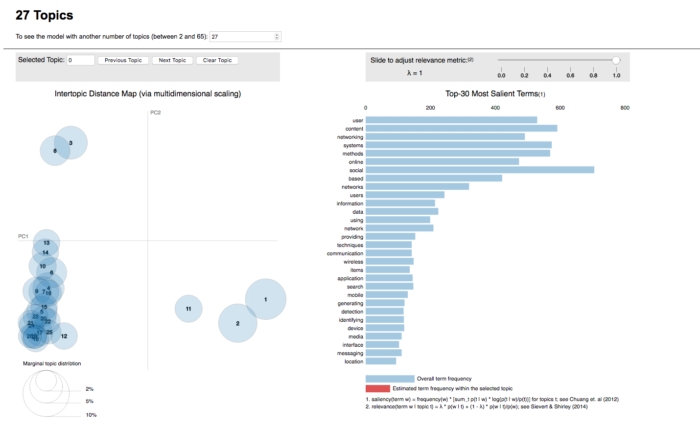
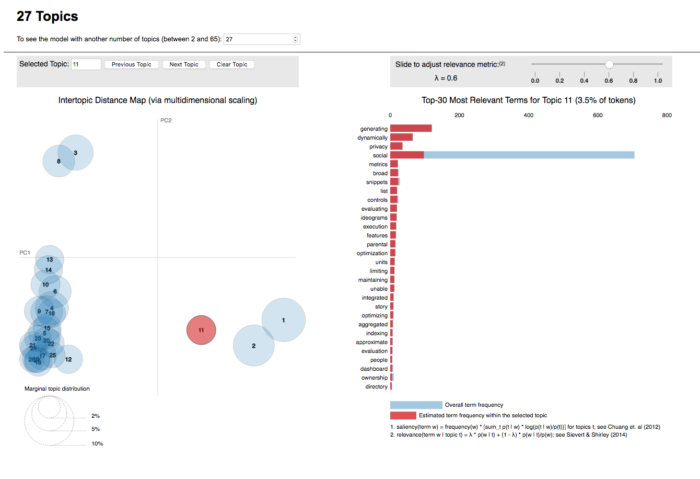
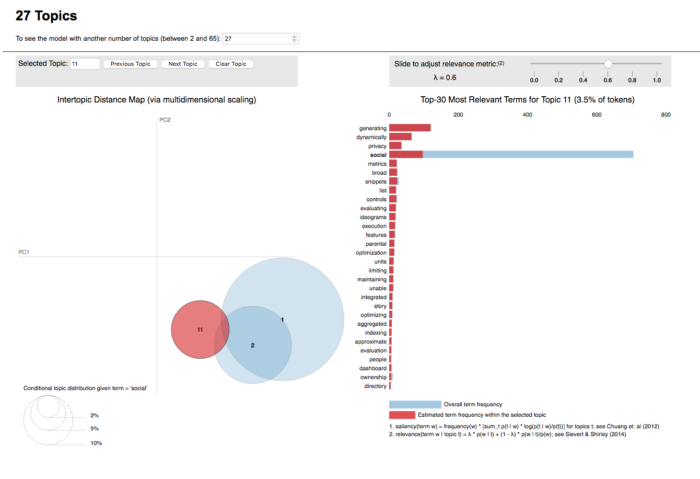
What is new about their tool is how they determine the most useful terms to interpret a topic (and also how users can interactively change it). They propose a measure called relevance, which is similar to exclusivity as defined by Bischof and Airoldi (2012): it denotes the degree to which a term appears in a particular topic to the exclusion of others. Relevance is based on another metric, lift – defined by Taddy (2011), which is the ratio of a term’s probability within a topic to its margin probability across the corpus. On one hand, it decreases the ranking of globally common terms, but on the other, it gives a high ranking to rare terms that occur in a single topic. In 2012, Bischof and Airoldi proposed a new statistical topic model that infers a term’s frequency and exclusivity (called the FREX score). The authors’ method is similar: a weighted average of the logarithms of a term’s probability and its lift.
Relevance
Relevance is denoted by λ, the weight assigned to the probability of a term in a topic relative to its lift. When λ = 1, the terms are ranked by their probabilities within the topic (the ‘regular’ method) while when λ = 0, the terms are ranked only by their lift. The interface allows to adjust the value of λ between 0 and 1.
The authors of the paper conducted a study to determine whether there was an optimal value for λ regarding the use of relevance to aid topic interpretation and found that value to be 0.6, as described in section 3 of their paper. In any case, it is very handy to be able to adjust that any time.
Interpreting the topics
Topic modeling is generally used to organize a collection of documents into a structured archive without having to read them all. It is used in other contexts as well, not only with text documents (clustering, for example, but also annotating images, network analysis, genetic data). In the context of this research, given that LDA is possibly a method used for Facebook in clustering, our interest lies in understanding how it works, and which elements are important.
One essential element within topic modeling is the definition of the number of topics around which the collection should be organized. This number determines how each topic will look like and which terms will be grouped together. After having tried visualize the composition of each topic (see previous post), I expected pyLDAvis to significantly decrease the difficulty in interpreting the topics using different topic numbers and by doing so, to help define the optimal number of topics for the data. I had briefly read about perplexity, a measure that indicates how ‘surprised’ the algorithm is to see a term within a given topic (lower values indicating better model) and in the meantime, while researching a bit further, I came across the possibility that perplexity might not be such a good metric, because – in short – it is context-free, i.e, it does not capture semantic information. Topic models that perform well according to perplexity tend to not be semantically meaningful.
Topic Coherence
In researching further, I found that a more appropriate method would be computing the Topic Coherence: a framework of coherence measures, composed of 4 steps:
-
- segmentation of words subsets;
- probability estimation;
- confirmation measure;
- aggregation.
It is a somewhat complex method, implemented in the Python Library gensim.
Topic Visualization
While experimenting with the topic model visualization, I produced several models (using different topic numbers) and looked at the results. However, as mentioned above, topic interpretation can be quite difficult – and time-consuming: a perfect occasion to use topic coherence as an aid in interpreting the topics. While producing the models, I saved the coherence values for each one of them. Unfortunately, these initial attempts did not yield any insights on that front yet, so I left the plotted graphic out of the post for now. Once I get more acquainted with topic coherence, I will revisit it and post my findings. Meanwhile, the data has been modeled (with number of topics varying from 2 to 65) and can be visualized in the link below.
https://objectorientedsubject.net/prototypes/pyldavis/index.php?topics=2
As always, comments are welcome.