Following our commitment to keep an active and periodic communication regarding the development of “Object-Oriented Subject”, my first post here in this blog will function as a report of my research notes, insights and intentions during the initial period of this project’s activities.
Advertising on Facebook | Facebook Business
One of the main sources of information relevant to this project, as selected by me and Lúcia, is Facebook’s own tools and tips for advertisers. Here you can find all the resources Facebook has available to help advertisers create an ad, manage it and measure its effects. I started my research with the exploring of the Ad Manager tool. The interface of the Ad Manager is divided as follows:
1) Campaign – Choose your campaign objective (awareness, consideration or conversion)
2) Ad Account
3) Ad set
3.1) Audience – Choose your audience (e.g.: based on demographics, behavior, interests, etc)
3.2) Placements (Facebook, Instagram & Audience Network; edit placements, etc)
3.3) Budget (payment (daily or lifetime); schedule (continuously or start & end date))
4) Ad
4.1) Pages
4.2) Format
4.3) Fullscreen Experience
4.4) Text
4.5) Ad Preview
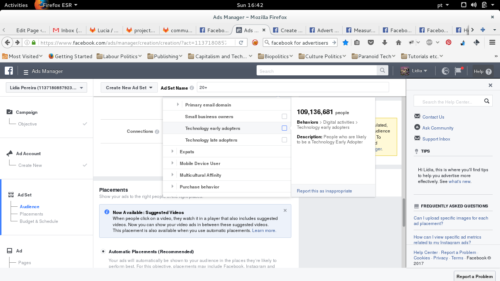
For the purposes of this research, the most interesting section of this tool is the Audience (3.1), as it is here one has access to all the categories Facebook deems relevant for the classification of its users. There are three main categories: DEMOGRAPHICS (incl. education, generation, home, life events, parents, politics (US), relationship, work), INTERESTS (incl. business and industry, entertainment, family and relationships, fitness and wellness, food and drink, hobbies and activities, shopping and fashion, sports and outdoors, technology) and BEHAVIOURS (incl. anniversary, digital activities, expats, mobile device user, multicultural affinity, purchase behaviour, seasonal & events, travel) So, for example, an advertiser can make an ad run for millenials OR college graduates who own a house AND like fast food OR who own a house AND are hispanic (US-bilingual). While it is somewhat clear that these specific categories (including sub and sub-sub-categories) were included for their demonstrated marketing efficiency, a detailed breakdown on the criteria for inclusion/exclusion is missing, as well as a detailed breakdown on the criteria for inclusion/exclusion of people into a given category. At this point, it is important that I underline that, for the purposes of this research, such clarification wouldn’t serve the goal of legitimizing these processes.
Following this preliminary analysis of the Ad Manager, I was interested in learning more about the different types of audience advertisers can select for their products. There are three options for choosing an audience on Facebook:
– one we have already talked about, the core audiences, in which advertisers manually select the desired characteristics based on Facebook’s given categories;
– custom audiences, where, among other options, advertisers can upload their contact list to connect with their customers of Facebook;
– lookalike audiences, where advertisers can use their customer information to find similar people on Facebook.
After exploring more about each of these, I got to another tool worth mentioning for its relevance to the whole process is Facebook Pixel. The Facebook Pixel is a piece of JavaScript or image tag that advertisers can copy on their website header.
Among other things, Facebook Pixel allows advertisers to measure the effectiveness of their ads by reporting peoples’ actions on their website. Another function of the Facebook Pixel is to help advertisers build custom audiences based on these same actions. As an example, the advertiser can create an audience for a specific ad based on the pages the future members of that audience visited. If someone was just about to buy a specific product but then he/she didn’t follow through with it, he/she might just find her/himself at the receiving end of an ad prompting the purchase of said product.
During this process, I also came across the Custom Audiences Terms of Service and the Advertising Policies. The most noteworthy (although expectable and quite frankly not surprising) takeout was the usage of abstract and vague terms to define and/or restrict certain behaviors. For example, supposedly advertisers must not use audience selection tools to wrongfully target or exclude specific groups for advertising – what, according to Facebook, is “wrongful”?
One other service Facebook provides to advertisers is constituted by Facebook IQ:
“Rooted in what we’ve learned from 2 billion people on our platforms and the 4 million businesses that advertise with us, Facebook IQ uncovers actionable insights about people, marketing and measurement available nowhere else. We offer studies, tools and resources built to transform how marketers reach people and deliver real results in this cross-channel, multi-device world.”
Facebook IQ offers advertisers their people and audience insights, such as information regarding the apps users above 45 years of age are using to stay fit or the trendy topics in the US for the month of July (these topics are measured in conversation volume + who’s driving the conversation by sex and age).
So far, the research into the tools Facebook makes available for advertisers has proved valuable in gaining a better understanding of the multiplicity of ways Facebook believes data can be made “meaningful” for the purposes of marketing and campaigning. It was also interesting to note the use of language, from the propaganda-like “People are their real selves on Facebook” to the abstract “we do not use sensitive personal data for ad targeting”, but always presenting itself as factual and neutral. In the future, some of my goals will be to better understand how user data is managed, mined and aggregated for the purposes of categorization, how the wide network of Facebook’s partners fits into this scheme, which categories are built from inferred data and how this data is inferred and, as I mentioned before, how exactly these categories exist and why.
Apply Magic Sauce & IBM Watson’s Personality Insights
Two of the machine learning API services behind Data Selfie(a Chrome extension who claims to want to give us back our Facebook data), Apply Magic Sauce and IBM Watson Personality Insights, offer a sneak preview into the inference of personality traits from data.
Apply Magic Sauce’s Demo takes either your Facebook Posts, your Facebook Likes, your Twitter feed or everything combined to predict your profile. You are then shown a result page with, among others, your predicted age, gender, Big 5 Personality Traits (Openness, Conscientiousness, Extraversion, Agreeableness and Neuroticism), Leadership Potential, Intelligence and Jungian Personality Type. Their methods behind these predictions are published and can be consulted, of which two of the titles:”Private traits and attributes are predictable from digital records of human behavior”(Kosinski, Stillwell & Graepel, 2013) and “Computer-based personality judgments are more accurate than those made by humans” (Youyou Wu., Kosinski M. & Stillwell D. 2015) we hope to further explore.
IBM Watson Personality Insights Demo takes either your Twitter personality or a body of text to predict your personality. You are shown a result page with, among others, your personality portrait, Big 5 Personality Traits and some likely and unlikely behaviors. A preliminary reading of their page “The Science Behind the Service” allows us to take the preliminary conclusion that these predictions were made based on the user’s use of language.
In the future, I hope to explore and understand the usage of similar services on and by Facebook.
“We Are Data” by John Cheney-Lippold
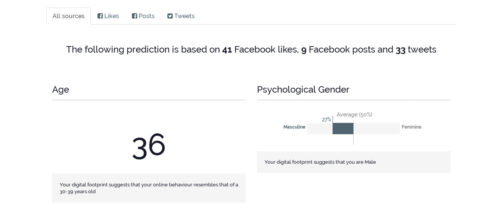
Last, but not least, the first book selected for complimenting my part of the research was “We are Data” by John Cheney-Lippold. Already in the introduction of the book fundamental concepts are explored, such as algorithmic caricature. This term refers to the disconnect between the online and the “real self” (whatever that might mean). For example, competing services have different portraits of the same people; our online identities become thus privatized. Google’s gender is not necessary your assigned gender – while reproducing the bias attached to social constructions of gender, Google’s gender is a marketing construct. For these services it doesn’t matter if you are male or female “in real life”, as long as your demonstrated interests and behaviors reflect the social construction of one or the other and can be marketed thus. The same goes for age. A very practical example was that my Apply Magic Sauce Demo’s personality prediction told me that I, a 27 year old female, was a 36 year old male based on my Facebook (likes and posts) and Twitter feeds.
[…] a look at and register the most basic entry points: the tools that Facebook makes available for advertisers and developers. Facebook’s tools for developers include Products, SDKs and […]
[…] have mentioned ‘measurable types’ here before, but I would like to explore this concept further as it is an important one to grasp the […]